Transfer learning experiment: ResNet with CIFAR-10
Abstract:
Using transfer learning, i trained a ResNet-50 with weights from the imagenet competition to the CIFAR-10 which has 10 classes only as opposed to the 1000 classes in the competition, the result was a Top-1 accuracy of 90%.
Introduction:
Making and training a model from scratch is a very time consuming task let alone a CNN in which depth is very important.
- This is explained by the variety of the implementation choices:
- The design and the architecture of the network.
- Regularization and Optimization
- Hyper parameter tuning
that’s why we use already trained models and that’s called transfer learning, in this article i will be covering how i trained a Resnet-50 model for the CIFAR-10 dataset in Keras and the results.
Materials and Methods:
The first thing to consider in transfer learning is choosing the model, for keras i had multiple choices of already trained models in the keras.applications API[1].
For this project i chosen the ResNet50[2] because of it’s minimal size and effeciency. Other models that i considered were EffecientNets[3] which where introduced in 2019, i didn’t opt for them because i was already having good results with ResNet and i don’t think they will be of much improvement although this has to be tested.
I’ve organized the project into four parts: fetching data, pre-processing data, fetching the base model and integrating it and lastly the training process.
Fetching data:
def get_data():
"""Initialize cifar-10 data."""
train, valid = keras.datasets.cifar10.load_data()
return train, validSince i’m using CIFAR-10[4], i’m fetching the data through keras with it’s keras.datasets API, which returns training and validation data which are 50000 images for training and 10000 for validation.
Preprocessing:
def preprocess_data(X, Y):
"""Preprocess Data."""
Y = tf.one_hot(Y, 10)
return K.applications.resnet50.preprocess_input(X), tf.reshape(Y, [Y.shape[0], 10])For labels i had to apply one-hot encoding and for the images i had to apply the same process as the resnet paper which consists of changing the color channels placements from RGB to BGR then you zero center each color channel (subtracting the mean) with respect to the imagenet dataset.
Modeling:
def create_model():
"""Create model from resnet50."""
base_model = K.applications.ResNet50(
weights='imagenet',
include_top=True,
pooling='max')
old_input = K.Input((32, 32, 3))
pre = K.layers.Lambda(lambda x: tf.image.resize(x, [224, 224]))(old_input)
inputs = base_model(pre)
outputs = K.layers.Dense(10, activation='softmax')(inputs)
model = K.Model(old_input, outputs)
return model, base_modelFor modeling i first fetched the resnet model with ready weights then i add a layer on top to change the image size to fit the model.
I added the final softmax layer then I bundled all the layers together into a new model, another important note is that i’m returning model and base model (resnet) for ability to freeze/unfreeze the base model.
Training:
# fine tuning
model.compile(optimizer=keras.optimizers.Adam(1e-5),
loss=keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
model.fit(x=X_train, y=Y_train, validation_data=(X_valid, Y_valid),
batch_size=64, epochs=2)
# freezing and training only the last layer
base_model.trainable = False
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
model.fit(x=X_train, y=Y_train, validation_data=(X_valid, Y_valid),
batch_size=64, epochs=4)
# Saving the model
model.save('cifar10.h5')
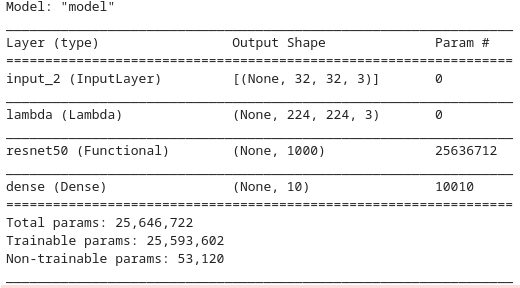
This is the most important and most time-consuming part of transfer learning, as here where the transfer happens, first i compiled the model with very low learning rate of 0.00001 and no frozen layers as in all the parameters are trainable, this process is called fine-tuning.
From my testing doing this really helped the model performance and i think this is because the model is readjusting the weights for a new problem domain, and from my testing 2 epochs of fine-tuning were optimal.
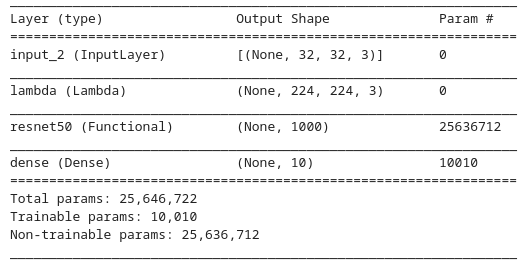
after the initial fine tuning i froze the base model and only trained the last added layer which pushed the accuracy further, with this the training is done.
Important:
This method was not recommended by the keras/tensorflow[5] tutorial instead they recommend doing fine-tuning after training frozen layers, this is because in the tutorial they didn’t use the top layer of the base model and added their own layers on top of the model.
Results:
With this approach i got an accuracy of 90% on the validation dataset and 92% accuracy in the training dataset, from my observation this can be further improved by performing fine-tuning again but i didn’t experiment with this.
