Regularization in Machine learning
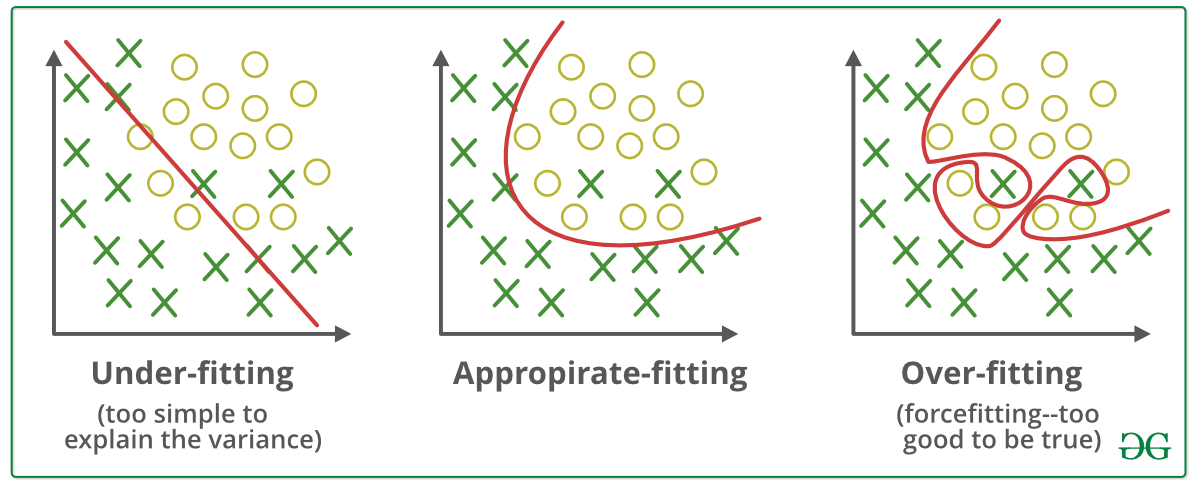
What is Regularization?
One of the biggest aspects in training machine learning models is avoiding over-fitting, it happens when our model aggressively fits to the training data which translates to high accuracy in training data but significantly lower one in testing data, this is the problem of over-fitting and it’s very prevalent in machine learning due to the data dependence of ML models, and this where Regularization comes into play, it’s techniques used to avoid over-fitting and achieve better results, the techniques we are covering are:
- L1 & L2 regularization
- Dropout
- Data Augmentation
- Early Stopping
L1 & L2 regularization
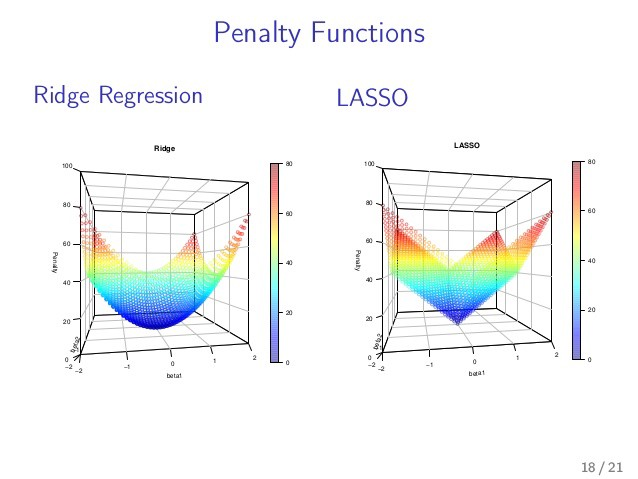
L1 and L2 regularization or LASSO and Ridge regression are regularization methods in which we focus on weight by reducing their values, this is why in fact they are also called weight decay, this introduces a kind of penalty system for weights to sort of “punish” high weight values and eliminate very low ones thus reducing over-fitting. Let’s break down this intuition! Let’s take the example of linear regression
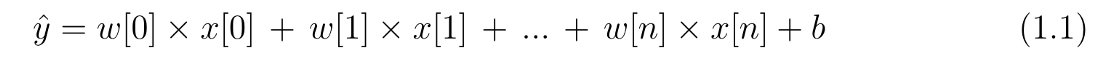
as we can see for linear regression we use w(weight) for the slope of the function and b will represent intercept, linear regression looks to optimizing w and b such that i minimizes the cost function below (least square):
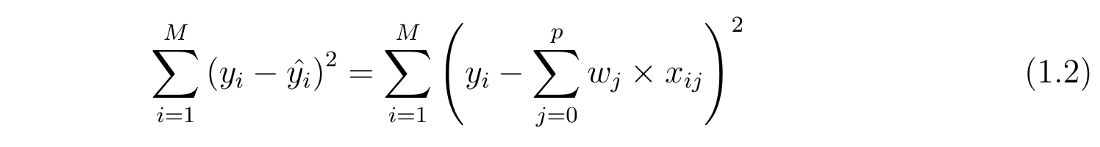
In L2 regularization the cost function is altered by adding a penalty equivalent to square of the coefficients (w) times a new hyper-parameter lambda that controls the magnitude of the regularization effect the more the more the effect is minimized.
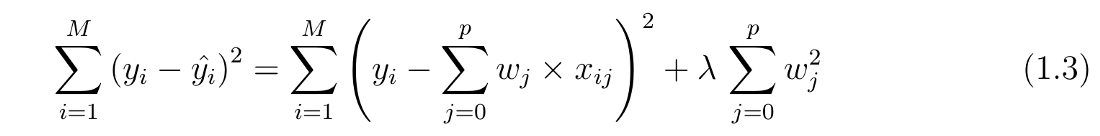
For L1 regularization the cost function is altered by adding a penalty in form of the absolute value of the coefficient or the norm (if we are dealing with vectors), like L1 we also have the hyper-parameter lambda that controls the regularization effect.
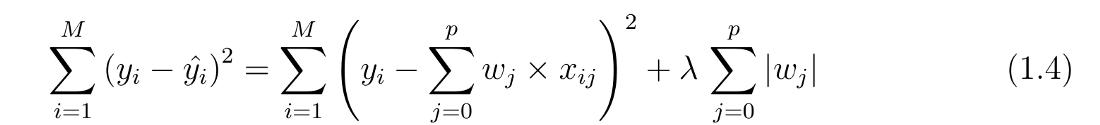
The difference between the two methods is that L2 regularization shrinks the less important features to zero thus it produces a feature selection effect by zeroing unimportant features.
Dropout
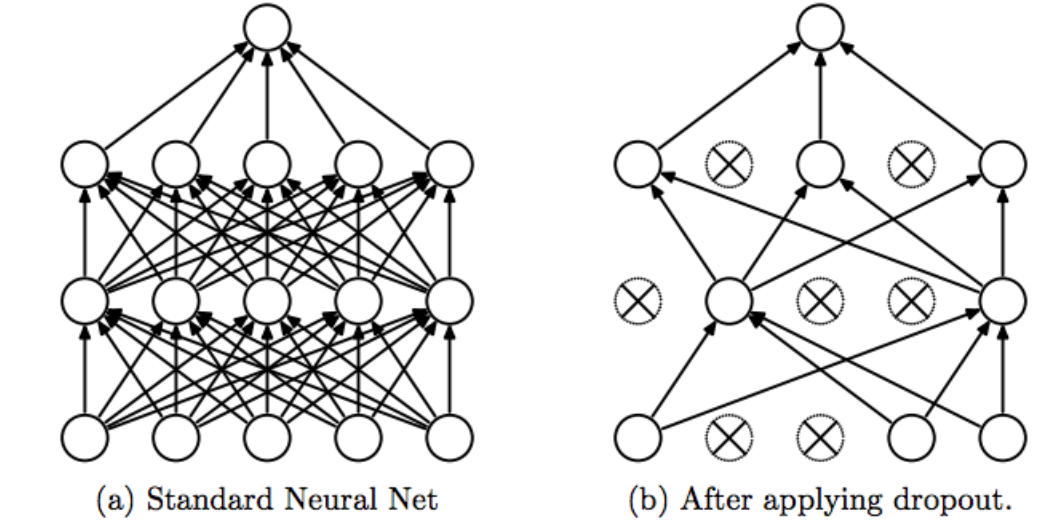
Dropout is my favorite regularization technique by how simple it is, It basically disables neurons randomly during training so that we avoid over-fitting, in testing this method researchers found out that it’s very effective in handling over-fitting.
It also introduces another hyper-parameter Drop rate (P) that represents the probability of each neuron to be turned off, Also for a neuron to be turned off we practically multiply the neuron output by zero.
Data Augmentation
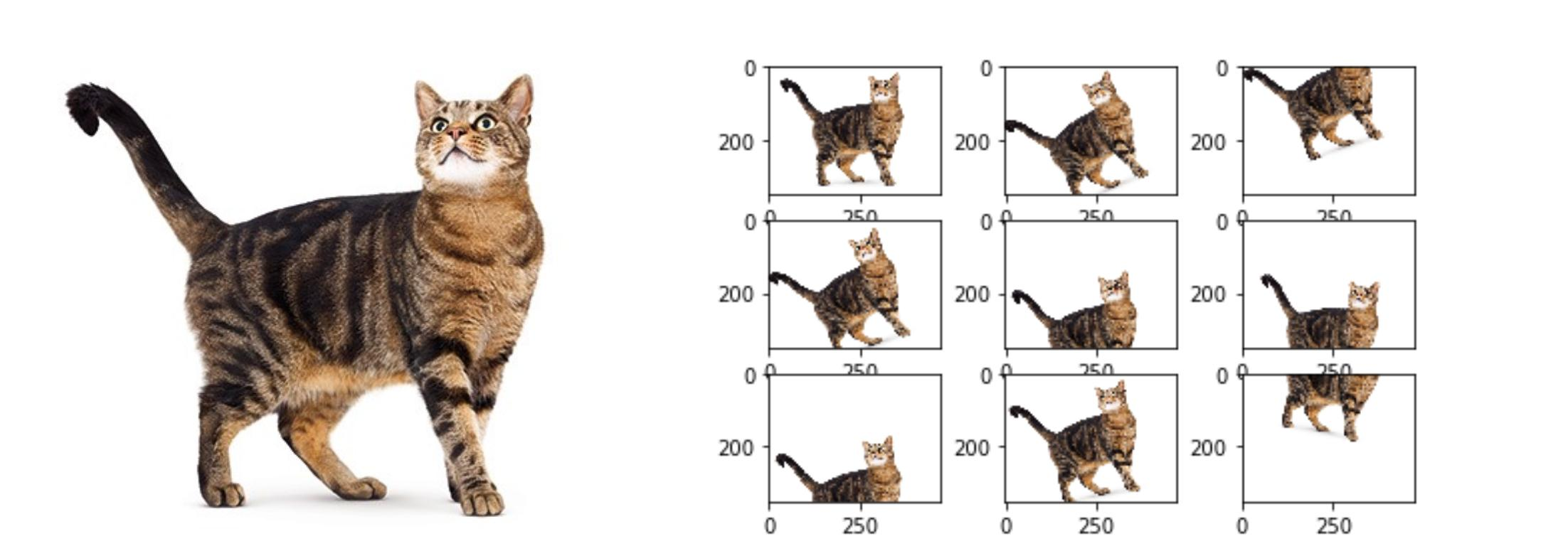
Data Augmentation is one of the most used regularization and it is becoming it is own discipline.
With a multitude of techniques data augmentation seeks to augment/add to our data another set of data by transforming the former and creating new entries for example we can apply flipping to an image, zooming into random places or even playing with the color channels.
These methods are widely used especially in the field of computer vision where data diversity and volume plays a huge role into the model performance.
Early Stopping
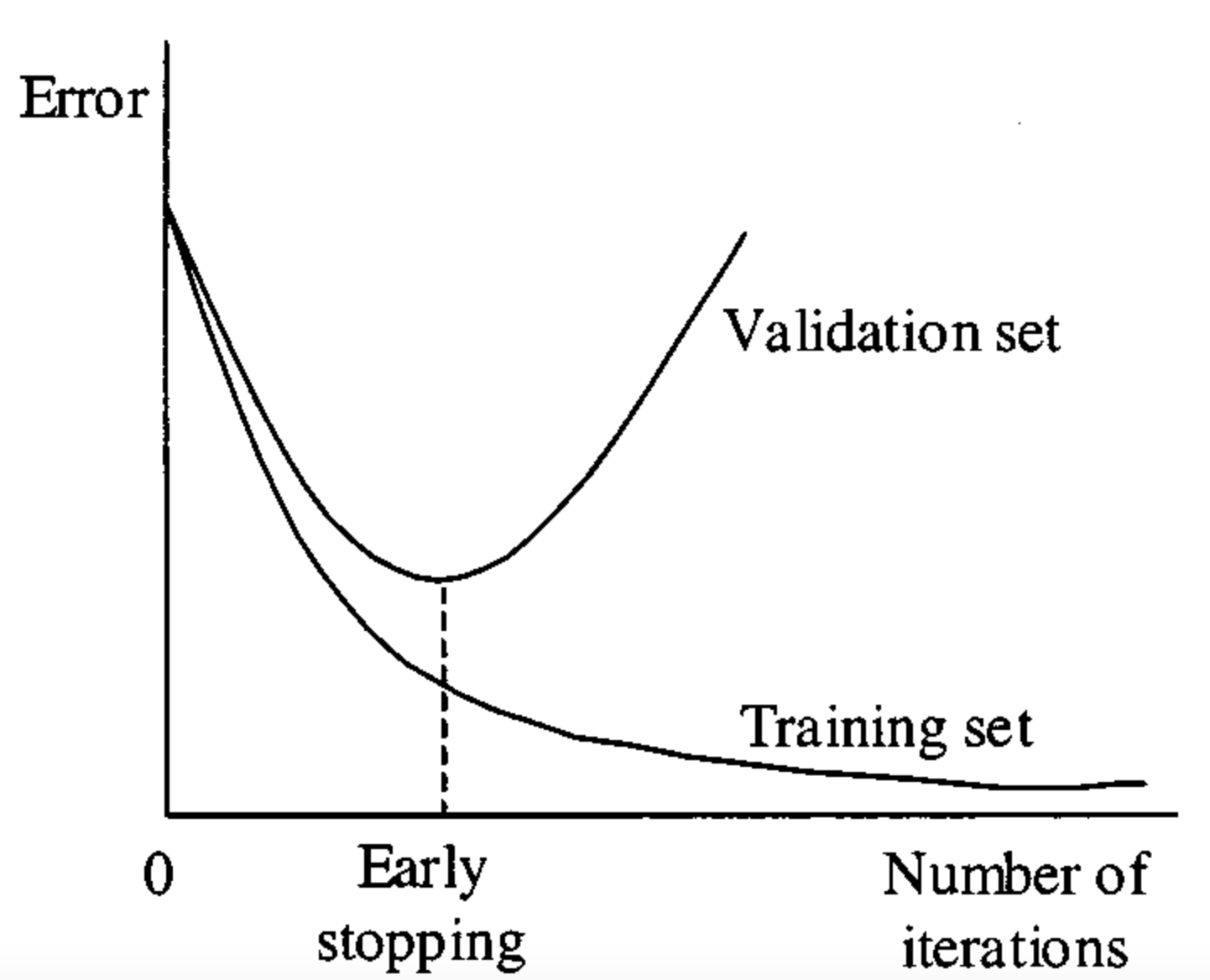
Early stopping a callback during training that seeks to automate the practice of stopping the training process when further training will only lead to over-fitting.
we predict over-fitting by looking at the error of the validation/testing set and when we detect that the error isn’t getting any better we stop the training, one of the ways to implement early is with the following parameters:
- validation cast: the current validation cost/loss.
- lowest validation cost: the lowest recorded validation cost.
- threshold: a threshold for early stopping
- patience: patience represents the degree of tolerance to which we allow the validation cost to not decrease
- count: a count of how many times the threshold has not been met
and the algorithm goes as follows: First we check if the difference between the the lowest validation cost and the current validation cost is above the threshold, If it is, we reset our count to zero which means the model isn’t over-fitting, If it is not we add to the count and if the count is the same as patience we stop the training.
Here’s the python function:
def early_stopping(cost, opt_cost, threshold, patience, count):
"""
Determine if you should stop gradient descent early.
cost is the current validation cost of the neural network
opt_cost is the lowest recorded validation cost of the neural network
threshold is the threshold used for early stopping
patience is the patience count used for early stopping
count is the count of how long the threshold has not been met
Returns: a boolean of whether the network should be stopped early,
followed by the updated count
"""
if (opt_cost - cost) > threshold:
count = 0
else:
count += 1
return (count == patience, count)Conclusion:
Over-fitting is a serious and regularly occurring problem thus learning the techniques to counter is an essential for every ML practitioner, with regularization we can avoid this problem with the cost of introducing more hyper-parameters, that’s where the field of hyper-parameter tuning comes into play.